
The Setup
This story is about a CI\CD pipeline we have at Data Masterminds that builds and deploys a database project. The code is in a repo in GitHub, and we have a couple of GitHub Actions that run when code is pushed to the development, or main branches - and then changes are deployed to the appropriate environment.
However, this post isn’t about how to set this up - if you want that, let me know and I’ll get to it! This post is about a problem I recently encountered.
The Problem
I recently made a change to a database schema that involved removing a column from a table. After we recently improved our authentication process to this tool we no longer needed a password field (don’t worry it was not holding plain text passwords!).
I made the change to the Users.sql file, built the project to confirm everything was good, and committed the change. But, on deployment my pipeline failed and this was the error The schema update is terminating because data loss might occur.
| |
That’s kind, and in most cases good practice!
Database DevOps is hard, and the main reason for that is we need to keep our data safe! The dacpac deployment step is configured with BlockOnPossibleDataLoss set to true. The deployment found that 6 Rows were detected in the table, and therefore refused to drop the column.
In some cases though, like what I have described here, we’re ok with data loss. I know that we don’t need that column, and I want it to be dropped.
So, how do you move forward when you do accept the change, and you are ok with the potential loss of data?
The Solution
There are a few ways around this solution, including manual deployment (gross), but instead I’ve added an additional option to our GitHub Actions that can be used when you’re ok with data loss.
As I mentioned there is a configuration called BlockOnPossibleDataLoss that is set to true by default. This, among other configurations can be controlled with a publish profile.
So, I created a second publish profile where this value is false, which means data loss is allowed. This is an XML file so the property looks like so:
| |
I left the GitHub Action to still trigger on commits with the regular publish profile, which blocks operations that will cause data loss. Then added a workflow_trigger with some inputs.
Adding a workflow_trigger allows you to navigate to the action within GitHub and manually kick off the workflow. What’s super neat about this is you can add inputs, that can then control what happens within the workflow. GitHub Actions are defined in yaml so this is what my action ended up as. You can see it still has the trigger for when code is pushed to, in this case, the main branch. Then a second trigger that takes an input of BlockOnPossibleDataLoss
| |
Here’s what the workflow_dispatch trigger looks like in the GitHub UI.
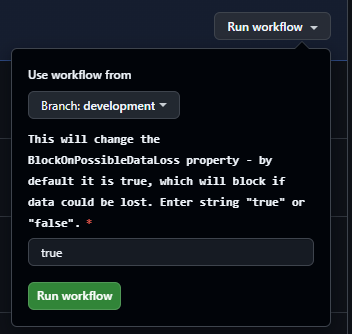
Further down in my action, within a PowerShell script task I have the code below.
| |
This code will evaluate the input and determine which publish profile to use. This means that on first attempt the dacpac deployment will not execute if there is potential for data loss as the input won’t be set, safety first! But, you have an override, kick off the action after changing the input property and you can carry on without having to manually build and deploy the dacpac.
The other benefit here for this method is that the deployment is still tracked within GitHub. One of the pros of pushing changes through CI\CD pipelines is that you can see exactly what was deployed when. If instead I pulled this repo locally to deploy you’d lose that trail (presuming I had permissions to do that… which if you’re deploying changes through GitHub, should you have those permissions? - an argument for another day)!
Header image by Jens Freudenau on Unsplash.